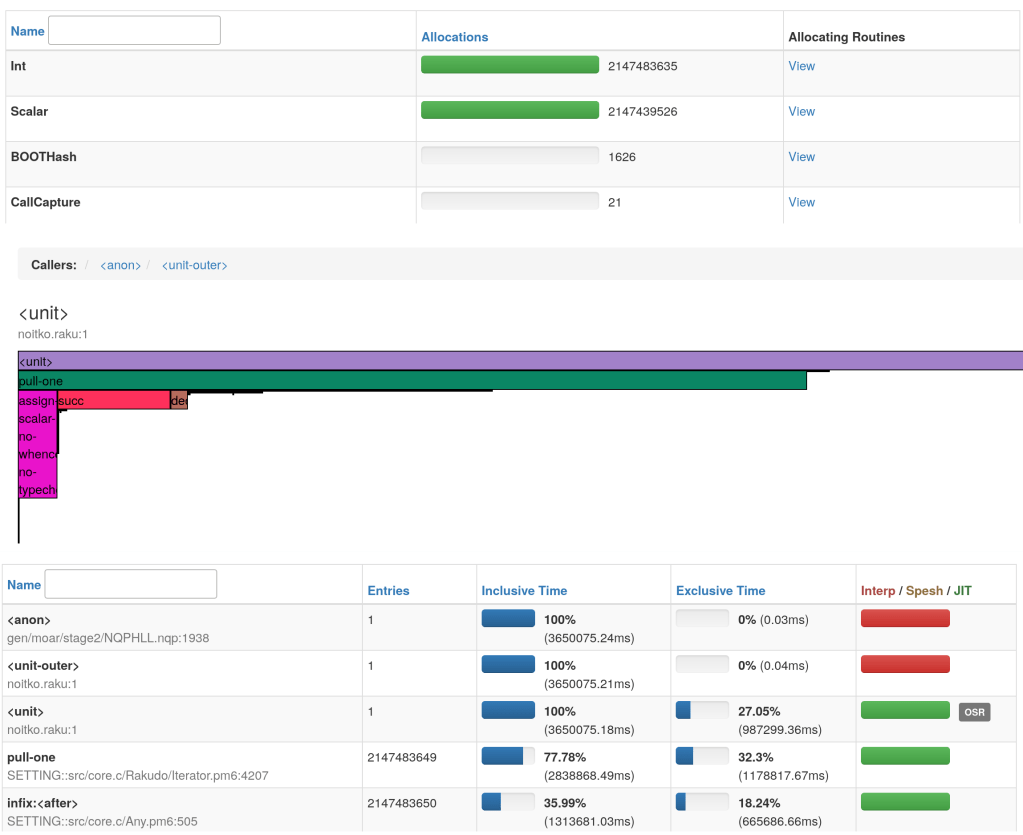
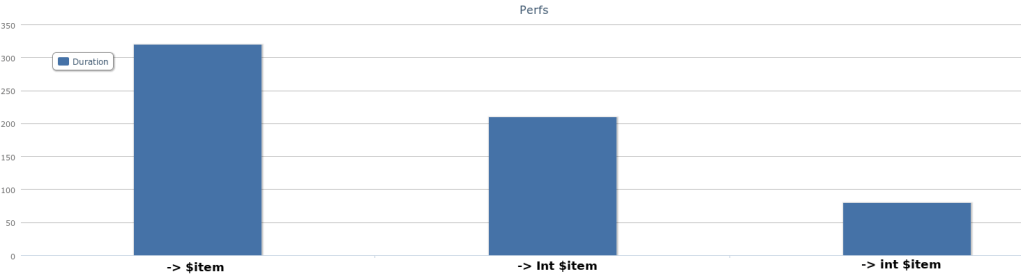
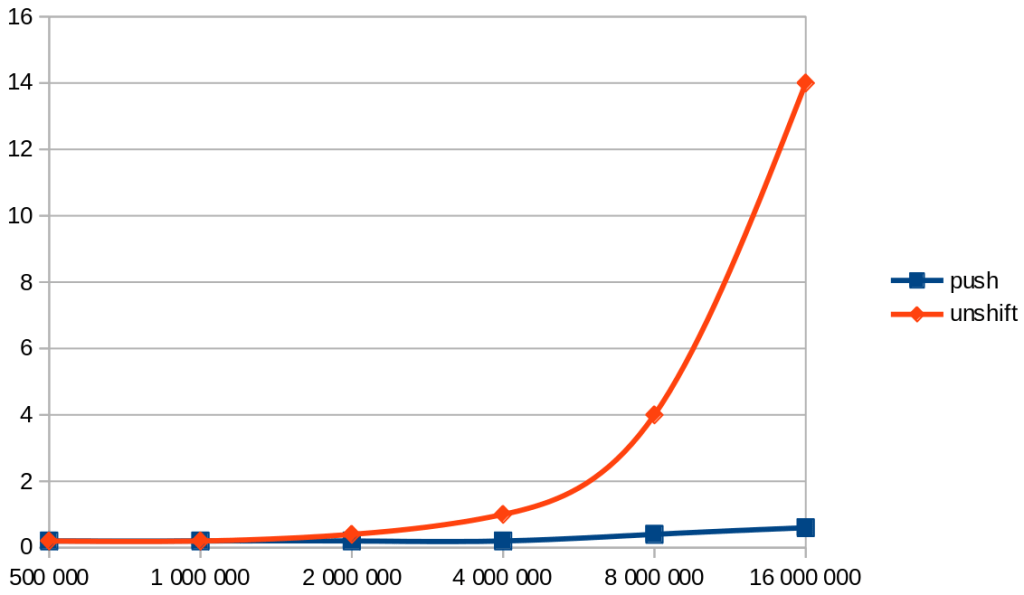
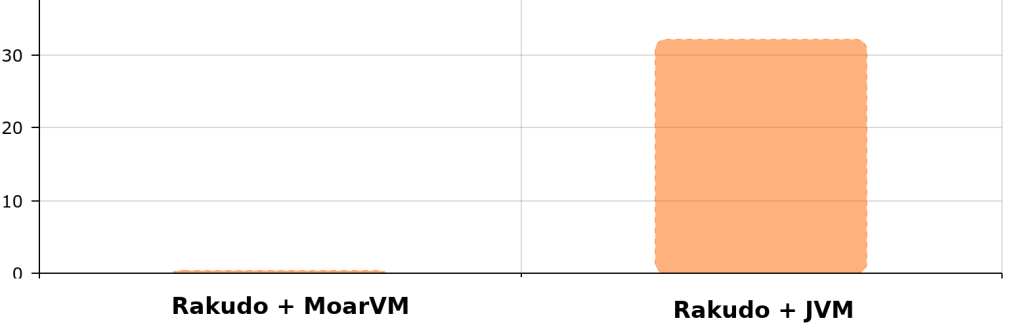
I’ve lived within a few minutes of a time zone border for most of my life. The way we distinguished time wasn’t with the official monickers of “Eastern” and “Central” time. No, we used the much more folksy (and yet, also much cooler) terms “fast time” and “slow time”. Knowing which zone you were talking about was extremely important as many people like my mother lived in one zone and worked in the other.
When I started looking at implementing internationalized DateTime formatters in Raku using data from the Common Linguistic Data Repository (or CLDR), I came to a fairly surprisingly realization: Raku doesn’t understand timezones! Sure, DateTime objects have the .timezone method, but it’s just an alias for .offset to figure out the offset from GMT.
Having lived in countries that did daylight savings time at different times of the year, having family in places in my own zone that don’t observe daylight savings time, and knowing that there are weird places with thirty- and even forty-five-minute offsets from GMT, I knew time zones could be complicated.
The universe is big, it’s vast and complicated, and ridiculous
There is a huge database simply called tz that is a huge repository of timezone data, from when transitions occurred, when daylight savings time when in and out off commission, offsets, everything. Unlike the Unicode code charts, Raku doesn’t include this as a part of its core because of its frequent updates and inherent instability (yay politicians). OTOH, probably in part to its origins as a real-life XKCD comic, it does include some very cool old-fashioned programmer musings which I fully advocate for us bringing back (when was the last time you saw a code base quoting literature in their header? Knuth?)
Alongside the database is a standard code library — one that’s likely on your computer if you’re using a *nix machine — to convert times from a variety of different representations while taking into consideration timezones. It’s written in C, so it’s highly portable.
We could have taken the easy way out and use NativeCall (a way to directly call compiled C code from within Raku) to pass in the data. But what’s the fun in that? Instead, I ported the code. After all, the algorithm is fairly simple consisting of tons of constants and some basic math, a few binary searches and a pair of conditional, but nothing that can’t be done in any language. Easy.
But once that’s done, there’s still a problem. How do we get DateTime to understand time zones?
Mastering time
Raku’s DateTime, as mentioned, doesn’t really understand time zones outside of knowing what a GMT offset is. I probably could have just made a new DateTimeTZ class for people to use in modules such as a date/time formatter that need to understand time zones but then I’d need to spend a lot of time ensuring that my code coerced between the two and didn’t accept/return the wrong ones and… yeah, that would be annoying. Plus, even if I made it a subclass of DateTime, because most DateTime methods return new DateTime objects, I’d need to override virtually every method, and even then, if someone other module created a DateTime manually from it, time zone information would be lost.
Another option could be to augment DateTime to give it a new .timezone-id and .is-dst method. Augmenting is the process of adding methods or attributes to a class outside of its original declaration. But it’s impossible to know looking at a time what it’s timezone ID is. While North America and South America share time zones by offset, they have different names (and adjust daylight savings time differently). I could try to infer, like with what Intl::UserTimezone does, but that would only work for timezones in the user’s current region at best, and still ultimately end up requiring the user to specify it in some way. Plus, when you augment something you break precompilation. Raku precompiles modules to reduce startup time, meaning that using time zones with any large module would wreck your start up time, especially if you use a few very large modules.
There had to be a better solution. That solution involved two solutions: one very common, and one rarer.
Adding a dash of wibbly wobbly timey wiminess.
The first thing that needed to be done was create a role that could be mixed in, that is, applied to a class. Roles are traditionally used to describe or modify behaviors (they are similar to Java’s interfaces), but they can also add extra information to existing classes. Roles also nicely allow typechecking to happen exactly as it would have for the base class, so by mixing one in with every DateTime there shouldn’t be any compatibility problems. A simple Timezone role might look like
role TimezoneAware {
has $.olson-id;
has $.is-dst;
}
I mean, this works. I need to be able to set those, and I’d rather not pollute things with a public instantiation method since roles can’t be passed attributes like classes can.But they can be parameterized. This might be an abuse but we can end up with …
role TimezoneAware[$tz-id,$dst] {
method olson-id { $tz-id }
method is-dst { $dst }
}
Now we have a way to make a DateTime know about its time zone but… how do we apply it? Asking users to manually state DateTime.new(…) does TimezoneAware[…] would get very tedious, especially since they can’t control DateTime objects that might be created from those (since DateTime is immutable, any adjustments like .later create a new DateTime object, which wouldn’t have the mixin).
Never throw anything away, Harry
The way we can get this to work (and without throwing out precompilation!) is by using the wrap routine. Wrapping allows us to capture a call as it’s being made, and intervene as necessary.
A simple wrapper that just lets us know something was called would be:
Foo.^find_method('bar').wrap(
method (|c) {
say "Called 'bar' with arguments ", c;
my $result = callsame;
say " --> ", $result;
$result;
}
);
Anytime someone calls .bar on a Foo object, Raku will output what the arguments are as well as the newly made object, and still return it so it doesn’t interference with program flow. Because we can obtain the result of the original and then do something with it, we have the opportunity to mix in our role and have it affect every single DateTime that’s created by just saying $result does TimezoneAware[…].
There was one small issue I found with using this technique and it’s due to DateTime’s .new being a multimethod. Using callsame (which would pass us to the original DateTime) uses all the original arguments, which makes it impossible for us to add new arguments like :daylight or :dst or whatever we want to call it because the original method will reject them.
If we use callwith, though, we can remove those extra arguments and even make modifications if our timezone processing called for it (and it ultimately did). But because of the way wrap interacts with multi methods, we end up calling the wrapped method again! When I was testing, I would occasionally get a DateTime with the role applied two or three times. Not good.
The solution was surprisingly simple. When the wrapped method was called again, I just needed to use callsame to get the original version. But how could I know whether I was calling it the first time or not? (Recall that we can’t add parameters and still use callsame!) Raku’s dynamic variables came to the rescue. At the beginning of the wrapped method, we do a quick check to see if we want the original or wrapped:
DateTime.^find_method('new').wrap(
method (|c) {
return (callsame) if $*USE-ORIGINAL;
...
}
);
Unfortunately, the way that Rakudo compiles this means that we can’t actually set this variable, because the my $*USE-ORIGINAL would necessarily come after. But, if you haven’t guessed, Raku has a solution for that 🙂 We know that the variable will be somewhere in the caller chain. By using the psuedo-package CALLERS, it’s possible to locate the variable up the call chain, without causing the compiler to install its symbol in our scope.
DateTime.^find_method('new').wrap(
method (|c) {
return (callsame) if CALLERS::<$*USE-ORIGINAL>;
...
}
);
It’s true that if someone uses this same name there could be a problem because CALLERS goes all the way up the calling chain. It might be possible to use just CALLER::CALLER::<$*USE-ORIGINAL> but the number of times to use CALLER:: might not be terrible consistent. For the actual module, I’ve chosen an even more unlikely name of $*USE-ORIGINAL-DATETIME-NEW. Magic variables are bad, I know, but the obscurity should be more than sufficient.
Dimensional transcendentalism is preposterous (but it works)
One issue of callsame, callwith and the like is that they work on the current method, which makes it harder to farm things out. There are some ways around it, but I ultimately found it easiest to include all logic in a single method.
To mimic the multi methods exactly, without calling my own subs, I used captures and signature literals. Note the wrapped method’s signature of |c, which collects all the arguments into c and allows for inspection thereof. As there are, effectively, two ways to create a DateTime, let’s tackle the easiest one first: from a single number.
...
if c ~~ :(Instant:D $, *%)
|| c ~~ :(Int:D $, *%) {
my $posix = c.list.head;
$posix = $posix.to-posix if $posix ~~ Instant;
my $tz-id = c.hash<tz-id> // 'Etc/GMT';
my $time = localtime get-timezone-data($tz-id), $posix;
my $*CALL-ORIGINAL = True;
return callwith(self, $posix, :timezone($time.gmt-offset))
but TimezoneAware[$tz-id, $time.is-dst];
}
The result of localtime is (presently) a Raku equivalent of the old and ubiquitous tm struct used in virtually all *nix systems and time libraries. Since we already have the POSIX time, we just pass in the new “timezone” and mix in the role and done.
There’s one small annoyance though. Consider the following now:
say DateTime.new(now).WHAT; # DateTime+{TimeZoneAware[…]}
Ugh. That’s a veritable mouthful. Is there any way we can change that? As it turns out, there is. I’m not going to say that you necessary should do this, but we want to be as in the background as possible. Before returning, we store the variable like so:
my $result = callwith( … ) but TimezoneAware[…];
$result.^name = 'DateTime';
return $result
Et violà, it looks totally normally, except it has those extra methods. Our new DateTime will pass for an old one, even if someone does a name-based comparison (of course, they should use probably use .isa or smartmatching, which would work without the name change).
Now we tackle the second method, which is from being given discrete time units. There is a gmt-from-local routine that takes the aforementioned tm struct along with a timezone and tries to reconcile the two to get a POSIX time (if you ask me for 2:30 on a day we spring forward… we’ll have problems). Once we have the POSIX time, then we can create things like before. I’ll spare you all the different ways that this type of creation can happen, but it’s easy enough to imagine (or you can look in the code itself).
For methods outside of new there isn’t a lot of work that needs to be done. Things like .day, .month, etc, should all work the same, since the original DateTime understands GMT offset.
The important one is to-timezone where all we need to do, really, is wrap it and call .new(self, :$timezone).
Life depends on change and renewal
Wrapping is actually a very pervasive thing: you cannot lexically scope it, and so if we wrap at INIT (the phaser fired when a script is launched), its effects are seen globally from the get-go. Except… there are two phasers that fire before INIT. They are BEGIN and CHECK, and they fire in the compilation phase where we can’t touch them. If someone were to create a DateTime in one of these blocks, it will still be a regular DateTime without our mixin. Consider the following:
my $compile-time = BEGIN DateTime.new: now;
What should we do about this? If it gets used later, it won’t have the attributes that users might depend on. How can we help this out?
Firstly, if the user calls .day, there won’t be a difference, so no problems there. But if the user calls, say, olson-id, we’re in trouble. No such method. Or is there?
Raku objects have a special (psuedo) method called FALLBACK that is called when an unknown method is called. If there isn’t already a fallback added, we can’t wrap it (e.g. .^find_method('FALLBACK').wrap(…)). Nonetheless, the same HOW that gives us ^find_method also gives us ^add_fallback, although its syntax is a bit trickier.
For example, for the Olson ID method, we can do the following:
INIT DateTime.^add_fallback:
anon sub condition ($invocant, $method-name --> Bool ) { $method-name eq 'olson-id' }
anon sub calculator ($invocant, $method-name --> Callable) { method { … } };
If the condition sub returns True, then the method returned in calculator is run. Now, even if one of these old school DateTime objects manages to stick around, we can do something. But what can we do? As it turns out, a lot… depending.
We could just try to run a fresh set of calculations. If the same old-fashioned DateTime has us call the method on it regularly, though, then we’re wasting a lot of CPU cycles. Instead, we can actually replace (or… regenerate) the object! While the trait is rw is fairly well-known, much less well-known is that it can exist on the invocant! The only catch is we need to have a scalar container for the invocant, which is done by giving it a sigil:
method ($self is rw: |c) {
$self = …
}
There is one small catch, though. If the DateTime is not in a container (for example, it’s a constant), we’re not only stuck, but the above method will error because is rw requires a writable container. In that case, we’ll need to fallback to recalculating each time. Small price to pay. But how can we even know? Or make it work since the above errors with unwritable containers? Simple answer: multi methods. Miraculously, if you have two identical methods, but for the trait is rw, then dispatch will prefer the is rw for writable containers, and the other for unwritables.
multi method foo ($self is rw: |c) {
self = … # upgrade for faster calls later
}
multi method foo ($self: |c) {
calculate-with($self) # slower style here
}
The catch is you can’t pass a multi method. In fact, multi methods can only be properly declared and referenced inside of a class declaration. The solution is to instead make a multi sub outside of wrap’s parentheses, and then refer to it with its sigiled self when wrapping:
proto sub foo (|) { * }
multi sub foo ($self is rw, |c) {
self = … # ^ notice the comma, subs don't have invocants,
} # but they're passed as the first argument
multi sub foo ($self, |c) {
calculate-with($self)
}
….wrap(&foo);
Wrapping, multiple dispatch, first-class functions, so much stuff going on but we avoid breaking precompilation and manage to not make a single use of MONKEY-TYPING 🙂
Bowties are cool
There are a lot of other little niceties that can be given for users. One of the primary issues is the name of methods and parameters. In the above write up, I’ve used some names, but could have used others. For instance, is there anything inherently better in using .is-dst versus .dst to determine if the given time is in daylight saving time? And outside of the is- question, should we use dst, daylight, or, like much of the world, summer-time?
Grabbing the timezone name presents similar issues. While stock DateTime has an .offset method to get the GMT offset, it also provides the exact same information from .timezone. Alternatives could be, as I used above, tz-id, timezone-id, or olson-id (Olson invented the IDs used when he made the database). Actually, on this one, I’ve cheated, slightly. By using the allomorphic IntStr, it’s possible for us to make something function differently in numeric and stringy contexts. So we can override timezone to return self.offset but self.timezone-id and it will probably give good DWIM functionality for everyone.
One that seemed fairly obvious was .tz-abbr, which gives information like EST or PDT for use in formatting. Nothing like having the method name exemplify what it gives 🙂
When creating a DateTime, it’s possible to also specify a formatter. The default follows an ISO standard, but a lot of people find, e.g. “CEST” much easier to recognize as being European than “+02:00”. Should the default formatter be changed? This is one I’ve not come to a conclusion on. The default provides a standard format, but since it can be changed, there’s no reason anyone should expect (or more importantly, depend upon) it to always produce the same string.
These may seem like trivial questions, but Raku prides itself on a culture of core and module developers really polishing things up to make them easy. Everything from code readability, integration with other modules and the core language, and functionality all get considered considered, and Raku in particular lends itself to giving developers the ability to do what’s best for both them and the users.
Don’t blink. Don’t even blink
Although I mentioned it briefly before, it bears repeating why Raku itself doesn’t contain support time zones out of the box. Time zones aren’t fixed. Government and politics are the wibbly wobbly to time zones’ timey wimey. I’m in the United States and Just because today I expect daylight savings time to start on March 14th, doesn’t mean that Congress or the US Secretary of Transportation (!) can’t change things tomorrow. Or my state, independently of the ones around it, may opt out of daylight savings entirely before then. Rinse and repeat for all the rest of the countries in the world.
Anything with baked in support needs to be incredibly stable (Unicode Character Database), or provide heads up for changes well in advance (leapseconds). This is because most people don’t use bleeding-edge distributions. Heck, Apple still distributes Perl 5.18.4 from 2013! In 2013 alone there were eight updates to the database, and since then there have been forty-five more updates up to today. Even for Python, which gets more update love from Apple, there have been twelve updates since the most recent version Apple distributes (2.7.16).
This is where modules can shine: by using zef or another module manager to upgrade DateTime::Timezones whenever there’s an update, users can always stay up to date. On the maintenance side, I’ve created a script that automates the entire update process, with me only needing to change the module’s version number and update documentation manually. This also means that if I don’t update the module for some reason, a local user can easily update the database locally on their own with zero knowledge of how the vagaries of the database work.
Event Two
As mentioned, I came to this project because my work on bringing the CLDR data to Raku, and specifically with formatting dates/times. One thing that it contemplates is support for non-Gregorian calendars, some of which differ quite substantially from the Gregorian in their manner of calculations. There are some like Jean Forget that are working on these for Raku, but they currently exist as their own separate classes that are not interchangeable with the built in Date and DateTime classes. There is nothing stopping anyone from further extending DateTime with the above methods to add in a new attribute calendar that can be set to gregorian or hebrew or persian. It would be a bit more involved than our work here, as some time calculations are hard coded into DateTime, it will require a fair bit of extra work, but is well within the realm of possibilities.
Our Perl brethren imagined different modules that shared common attributes, but with work, it ought to be possible for one DateTime to rule them all in Raku (wait, I’m changing cultural reference points, oops). Only … um, time, uh, will tell.