Introduction
This blog post discusses the development of graph theory algorithms in Raku. Moderate number of examples is used.
TL;DR: Just see the mind-map and then browse the last section with a graph that resembles a snow-covered Christmas tree.
In the post:
- All computational graph features discussed are provided by “Graph”.
- Graph plotting is done with:
js-d3-graph-plot, provided by “JavaScript::D3”.Graph.dot, that makes SVG images via Graphviz.
Graph theory functionalities making
Because of a few “serious” projects involving conversational agents about logistics I thought that is a good idea to have geographical shortest path finding in Raku. (Instead of “outsourcing” those computations to some other system.)
The assumptions were that:
- The fundamental graph algorithms are (relatively) easy to program.
- Just good core data structures have to be chosen.
- Data and algorithms for simple graphs should be easy to implement.
The above assumptions turned true, in general, and while graph-programming with Raku, in particular.
The Raku package “Graph” provides the class Graph that has the following classes of algorithms (as class methods):
- Finding paths, cycles, and flows
- Finding shortest path, hamiltonian path, etc.
- Matching and coloring
- Graph manipulation
- Edge removal, vertex replacement, etc.
- Graph-to-graph combinations
- Union, difference, etc.
- Construction of parameterized graphs
- Complete, star, wheel, etc.
- Construction of model distribution based random graphs
- Watts-Strogatz, Barabási–Albert, etc.
The class Graph uses a map of maps for the adjacency lists (i.e. vertex connections.) It should be extended to have vertex- and edge tags. Having multiple edges should be supported at some point, but I consider it low priority.
Now, Graph theory is a huge field and this inevitably produces a certain opinionated selection of which algorithms to implement first or implement at all. It is natural to consider having (1) a set of implemented fundamental graph algorithms and (2) a framework for quicker developing of new ones. Currently, I would say, the former is fairly well addressed. It is in my future plans to have a user-exposed framework implementation based on Depth-First Search (DFS) and Breath-First Search (BFS) algorithms.
Graphs are naturally related to sparse matrices and many graph algorithms can be recast into sparse matrix algebra based algorithms. Because of this relationship and because sparse matrices are a very useful mathematical tool I implemented the packages “Math::SparseMatrix” and “Math::SparseMatrix::Native”.
The current functionalities of Graph are demonstrated and explained in the “neat examples” videos and blog posts. Here is a list of the videos in order of their making:
- “Graph neat examples in Raku (Set 1)”
- “Sparse matrix neat examples in Raku”
- “Graph neat examples in Raku (Set 2)”
- “Graph neat examples in Raku (Set 3)”
- “Chess positions and knight’s tours via graphs (in Raku)”
Here is a mind-map of the current development status of “Graph” that should give an idea of the scope of the project:
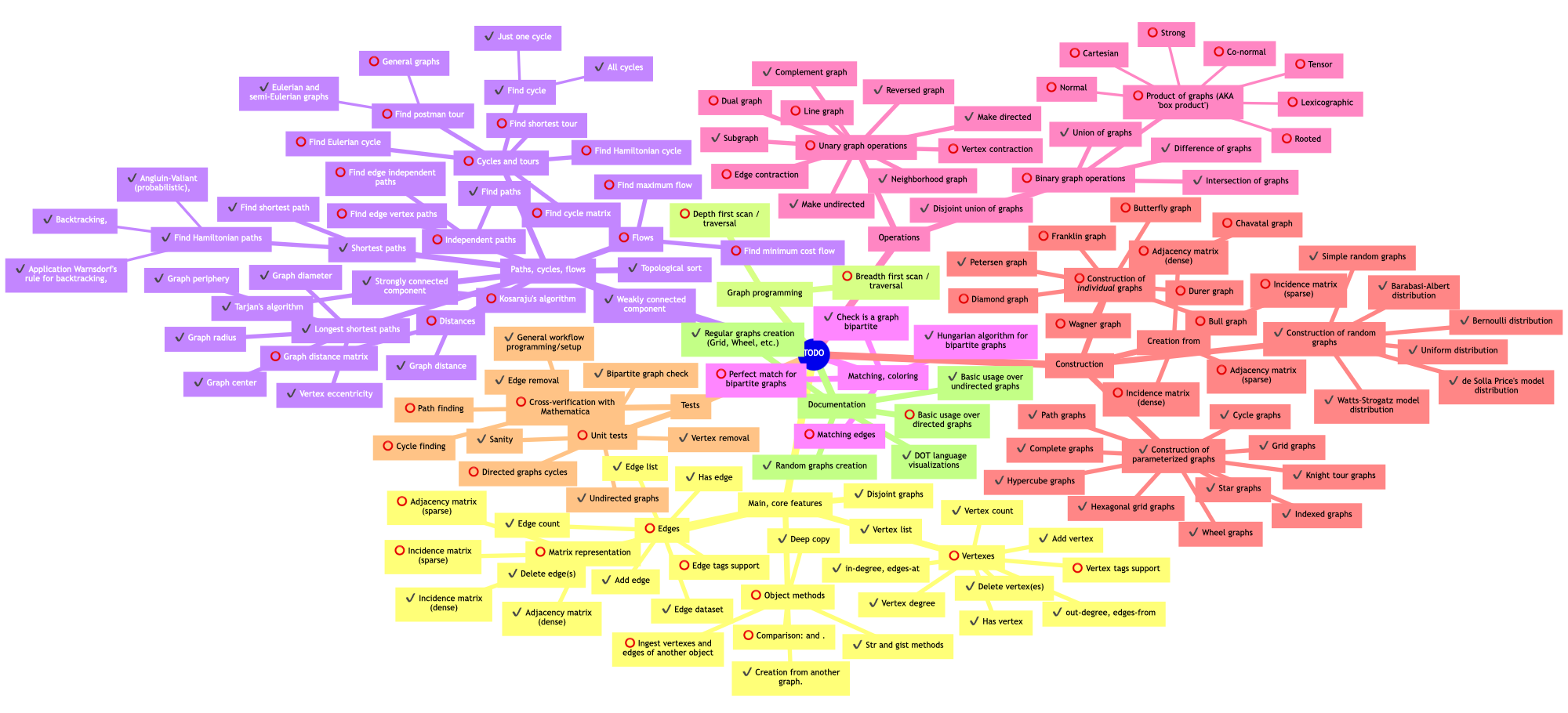
Remark: The mind-map above was LLM-created automatically from the README of “Graph” and a specially crafted prompt. The checkmark “✔️” means “implemented”; the empty circle “⭕️” means “not implemented” (yet.)
Spanning tree for large cities of USA
In relation to the Geo-motivation projects mentioned above let us consider the problem of building an interstate highway system joining the cities of USA.
Here is the available Geographical data from “Data::Geographics”:
city-data().map(*<Country>).unique.sort# (Botswana Bulgaria Canada Germany Hungary Russia Spain Ukraine United States)Here is a dataset of large enough cities:
my $maxPop = 200_000;
my @cities = city-data().grep: {
$_<Country> eq 'United States'
&& $_<Population> ≥ $maxPop
}
@cities.elems
# 126
Remark: Geographical data and geo-distance computation is provided by “Data::Geographics”.
#% html
@cities.head(4)
==> to-html(field-names => <ID Country State City Latitude Longitude Elevation LocationLink>)
Here is the corresponding weighted complete graph:
my %coords = @cities.map({ $_<City> => ($_<Latitude>, $_<Longitude>) });
%coords .= grep({ $_.key ∉ <Anchorage Honolulu> });
my @dsEdges = (%coords.keys X %coords.keys ).map: {
%(from => $_.head,
to => $_.tail,
weight => geo-distance(|%coords{$_.head}, |%coords{$_.tail} )
)
}
my $gGeo = Graph.new(@dsEdges, :!directed)# Graph(vertexes => 122, edges => 7503, directed => False)Here is the corresponding spanning tree:
my $stree = $gGeo.find-spanning-tree(method => 'kruskal')# Graph(vertexes => 122, edges => 121, directed => False)Here is an example of finding the shortest path from Seattle to Jacksonville in the spanning tree.
my @path = $stree.find-shortest-path('Seattle', 'Jacksonville')# [Seattle Spokane Boise City Reno Sacramento Stockton Modesto Fresno Bakersfield Santa Clarita Los Angeles Long Beach Anaheim Santa Ana Irvine Riverside Fontana San Bernardino Enterprise Henderson Glendale Phoenix Scottsdale Mesa Gilbert Tucson El Paso Albuquerque Amarillo Oklahoma City Tulsa Little Rock Memphis Nashville Huntsville Birmingham Montgomery Columbus Jacksonville]And here is the plot of the spanning tree and with the shortest path highlighted:
#% js
$stree.edges
==> js-d3-graph-plot(
vertex-coordinates => %coords.nodemap(*.reverse)».List.Hash,
highlight => {SlateBlue => [|@path, |Graph::Path.new(@path).edge-list] },
title => "USA, cities with population ≥ $maxPop",
width => 1400,
height => 700,
:$background, :$title-color, :$edge-thickness,
vertex-size => 4,
vertex-label-font-size => 12,
vertex-label-font-family => Whatever,
margins => {right => 200}
)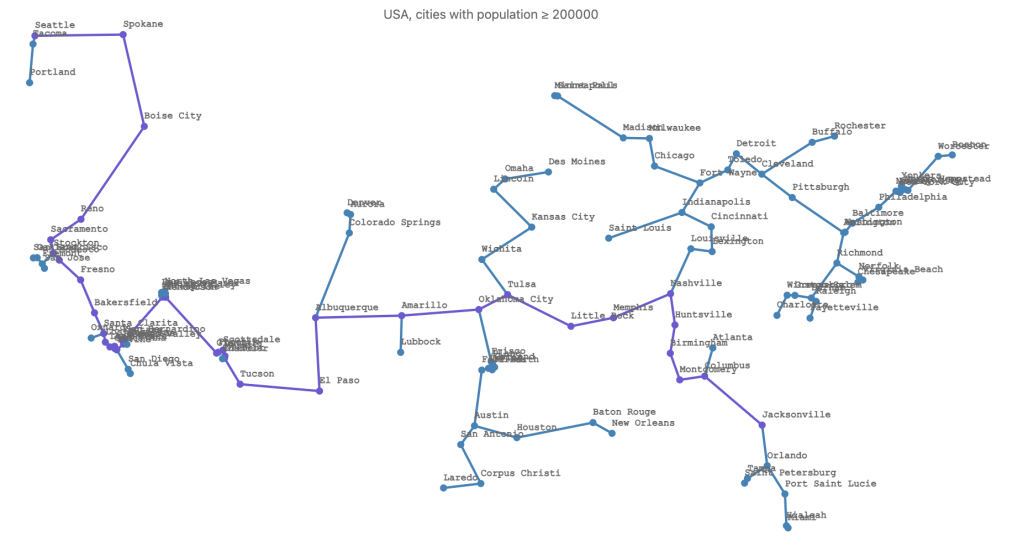
Remark: Using highlight => @path would just highlight the vertices, without the edges.
Remark: Would have been nice to use the spec highlight => Graph::Path.new(@path)instead of highlight => [|@path, |Graph::Path.new(@path).edge-list]. But I try to minimize the package dependencies of the Raku packages I implement, and because of that principle, “JavaScript::D3” does not know “Graph”. Hence, both vertices and edges have to be given to the “highlight” option.
Visualization
Graph visualization is extremely important for the development of graph software. (Meaning, it speeds up the development tremendously.)
Immediately after I implemented the first few “main” algorithms I made the corresponding Wolfram Language (WL) and Mermaid-JS representations methods of Graph. Soon after, I implemented js-d3-graph-plot in “JavaScript:D3” — D3.js has very nice network force functionalities. (“Network” is the D3.js lingo for “graph.”)
Since, the using of JavaScript plots rendering in Jupyter notebooks is somewhat capricious, I looked for alternatives. This lead to a “full blown” Graphviz plot support in Graph. (More about that below.)
JavaScript visualization
The plotting with D3.js (via “JavaScript::D3”) made me very enthusiastic to implement- and curious to see how different named and/or parameterized graphs would look visualized. So, I quickly made half a dozen of them. These graphs have known properties, which makes them good for algorithm development testing.
Here is a map (dictionary) with most of the currently implemented parameterized graphs:
my %namedGraphs =
Circulant => Graph::Circulant.new(7, 3),
Complete => Graph::Complete.new(5),
CompleteKaryTree => Graph::CompleteKaryTree.new(3,3),
Cycle => Graph::Cycle.new(8),
Grid => Graph::Grid.new(4,3),
TriangularGrid => Graph::TriangularGrid.new(3,3),
HexagonalGrid => Graph::HexagonalGrid.new(2,2),
Hypercube => Graph::Hypercube.new(4),
KnightTour => Graph::KnightTour.new(6,4),
Path => Graph::Path.new('a'..'g', :directed),
Petersen => Graph::Petersen.new(),
Star => Graph::Star.new(5),
Wheel => Graph::Wheel.new(7, :!directed),
;
.say for %namedGraphs# Star => Graph(vertexes => 6, edges => 5, directed => False)
# TriangularGrid => Graph(vertexes => 16, edges => 33, directed => False)
# Grid => Graph(vertexes => 12, edges => 17, directed => False)
# Complete => Graph(vertexes => 5, edges => 10, directed => False)
# Path => Graph(vertexes => 7, edges => 6, directed => True)
# Cycle => Graph(vertexes => 8, edges => 8, directed => False)
# Circulant => Graph(vertexes => 7, edges => 7, directed => False)
# Hypercube => Graph(vertexes => 16, edges => 32, directed => False)
# Petersen => Graph(vertexes => 10, edges => 15, directed => False)
# CompleteKaryTree => Graph(vertexes => 13, edges => 12, directed => False)
# Wheel => Graph(vertexes => 8, edges => 14, directed => False)
# KnightTour => Graph(vertexes => 24, edges => 44, directed => False)
# HexagonalGrid => Graph(vertexes => 16, edges => 19, directed => False)#%js
%namedGraphs.pairs.sort(*.key).map({
js-d3-graph-plot(
$_.value.edges(:dataset),
vertex-coordinates => $_.value.vertex-coordinates,
:$background, :$title-color, :$edge-thickness, :$vertex-size,
directed => $_.value.directed,
title => $_.key,
width => 300,
height => 300,
force => {charge => {strength => -200}, link => {minDistance => 40}}
)
}).join("\n")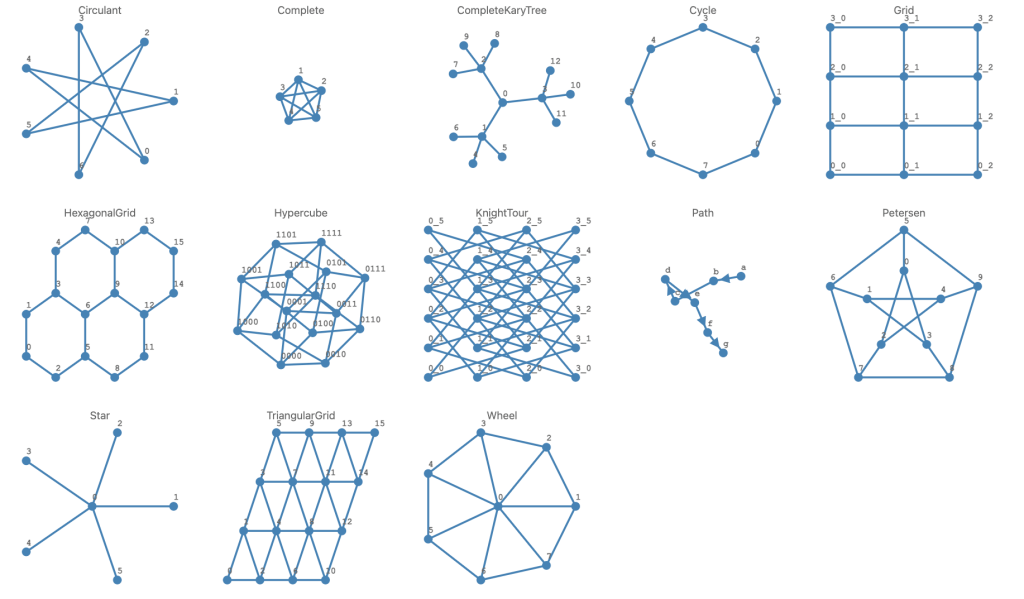
Of particular interest to me are the random graphs:
- Simple vertex- and edge sampling random graphs are useful for testing
- Well known random graphs that adhere to particular models are also very nice to have
The easiest way to have random graphs implementations is to have a special Graph::Distribution class.
Here are examples:
my %randomGraphs =
Barabasi-Albert => Graph::Random.new(Graph::Distribution::BarabasiAlbert.new(20,2)),
"Price's model" => Graph::Random.new(Graph::Distribution::Price.new(14, 2, 1)),
Random => Graph::Random.new(13,16),
Watts-Strogatz => Graph::Random.new(Graph::Distribution::WattsStrogatz.new(20,0.07)),
;
.say for %randomGraphs# Watts-Strogatz => Graph(vertexes => 20, edges => 44, directed => False)
# Barabasi-Albert => Graph(vertexes => 20, edges => 34, directed => False)
# Random => Graph(vertexes => 13, edges => 16, directed => False)
# Price's model => Graph(vertexes => 14, edges => 24, directed => True)#%js
%randomGraphs.pairs.sort(*.key).map({
js-d3-graph-plot(
$_.value.edges(:dataset),
:$background, :$title-color, :$edge-thickness, :$vertex-size,
directed => $_.value.directed,
title => $_.key,
width => 400,
force => {charge => {strength => -200}, link => {minDistance => 40}}
)
}).join("\n")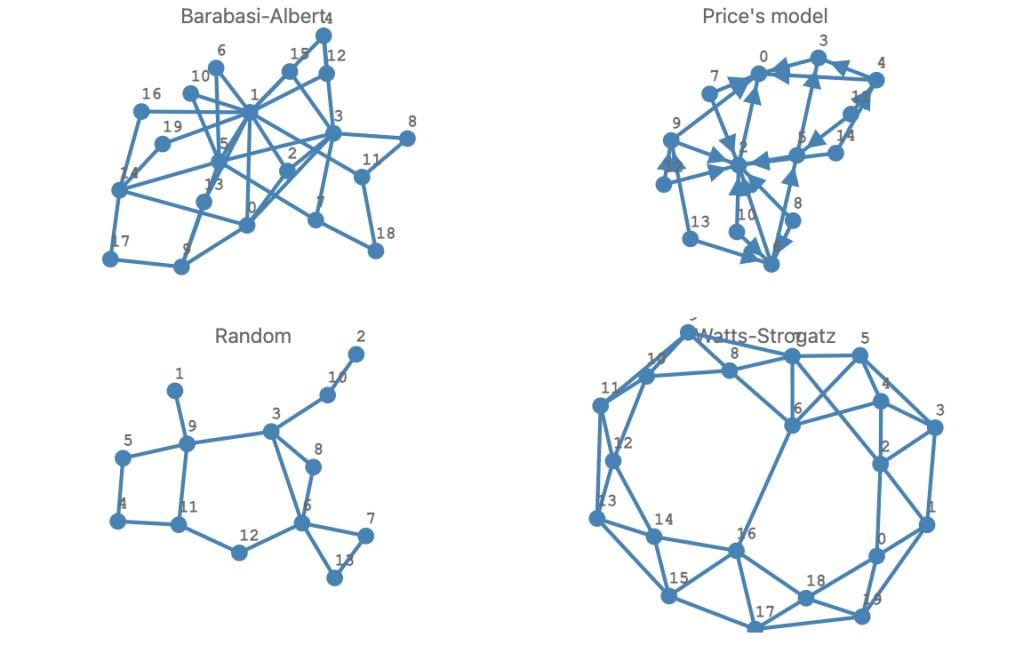
Graphviz visualization
Graph has the method dot that translates the graph object into a Graphviz DOT language spec.
#% html
%randomGraphs<Watts-Strogatz>.dot(:$background, engine => 'sfdp', :svg)
Using the “neato” layout engine graph objects that have vertex coordinates are properly plotted:
#% html
Graph::KnightTour.new(4, 6).dot(:$background, engine => 'neato', :svg)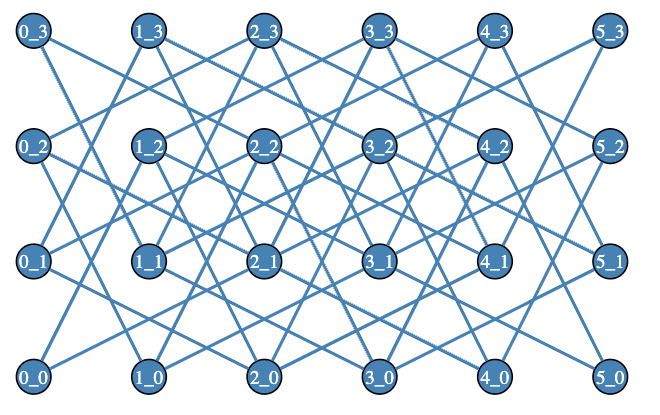
Also the Graphviz DOT representations can be used to plot chessboards, (via “Graphviz::DOT::Chessboard”):
#% html
dot-chessboard(:4r, :6c):svg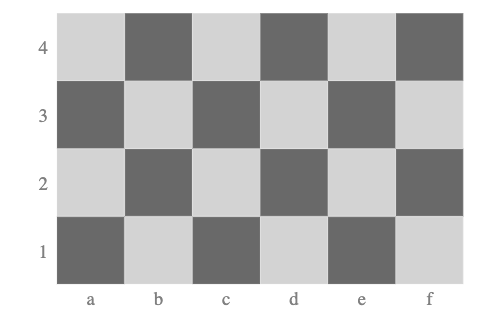
How come I invested so much in Graphviz DOT support in Graph?
Interactive plotting with D3.js is fairly unreliable Raku-wise — I can only use it in VSCode with Jupyter.
It was working in web browsers with the old Jupyter notebook framework. But after JupyterLab was introduced, my newest Jupyter-anything installations do not work with the JavaScript settings for plotting. (But making of static HTML pages with D3.js plots is fine.)
So, finding a more robust and universal alternative was really needed. After some discussion with a Raku-enthusiast known as “timo” I made finding such alternatives a priority.
So, I looked for JavaScript alternatives to plot graphs first. I was also looking — separately — for JavaScript-based ways to use the Graphviz DOT language.
At some point I figured out that Graphviz layout engines are fairly install-able / deploy-able in many operating systems, so just using Graphviz to generate SVG, PNG, etc. is both fine and reliable.
Sparse matrix representations
As it was mentioned above, graphs have a natural representation as sparse matrices. We can use the package “Math::SparseMatrix” to make those representations and “JavaScript::D3” to plot them.
Here are the sparse matrices corresponding to the parameterized graphs created and plotted above:
#% js
%namedGraphs.sort(*.key).map({
my $g = $_.value.index-graph;
my $m = Math::SparseMatrix.new(
edge-dataset => $g.edges(:dataset),
row-names => $g.vertex-list.sort(*.Int)
);
js-d3-matrix-plot($m.Array,
plot-label => $_.key,
width => 230,
margins => 30,
:!tooltip,
:$title-color,
:$tick-labels-font-size,
:$tick-labels-color
)
}).join("\n")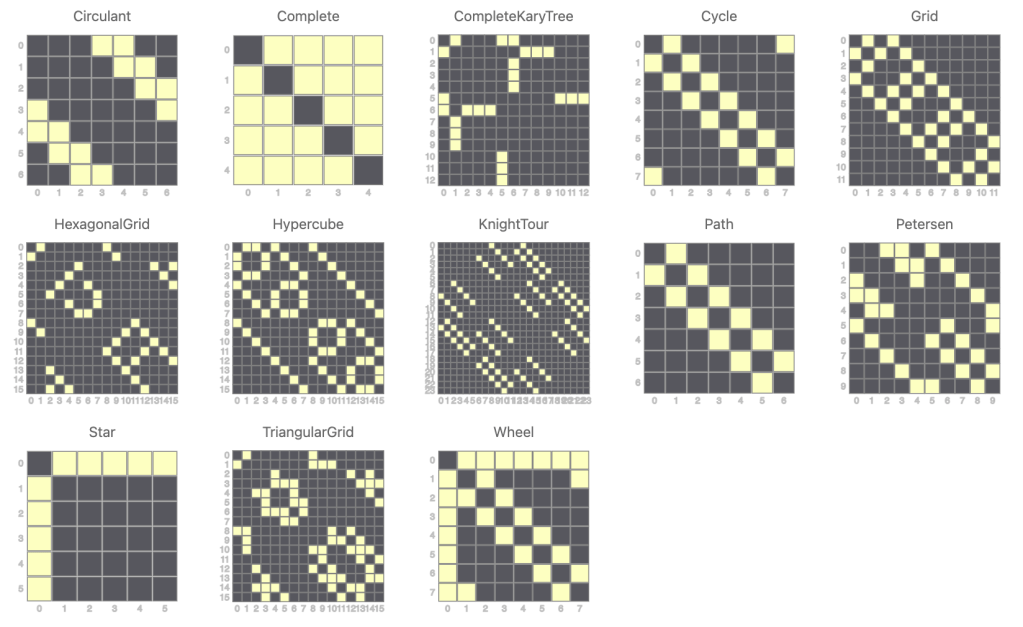
For more examples see the video “Sparse matrix neat examples in Raku”.
Christmas themed example
Let us finish this post with a topical example — we make a graph that looks like a Christmas tree and we color it accordingly.
Here is the procedure outline:
- Get a regular grid graph
G. - Get a tree-shaped subgraph
TofG. - Pick random vertices in
Tand remove their corresponding neighborhood graphs fromT.- Denote the new graph
X.
- Denote the new graph
- Find the vertices
vofXthat have degree less than 5. - Plot
Xby highlightingv.- The highlights can be randomly selected shades of a certain color.
The procedure is followed below.
Here we create a (largish) triangular grid graph:
my $g = Graph::TriangularGrid.new(30, 30);# Graph(vertexes => 976, edges => 2760, directed => False)Here we plot of a smaller version of it:
#% html
my $gSmall = Graph::TriangularGrid.new(3,3);
$gSmall.dot(
engine => True,
highlight => Graph::Path.new(<5 7 8 10>),
node-labels => False,
edge-thickness => 8,
node-font-size => 30,
node-width => 0.6,
size => 4
):svg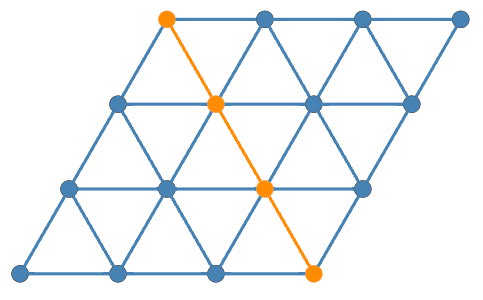
We plan to take the graph under the highlighted (orange) vertices and edges and turn it into a Christmas tree. (Or something that resembles it.)
Remark: Note that with Graph.dot we can use a graph object as a highlight spec.
Derive rectangular area boundaries:
my ($min-y, $max-y) = $g.vertex-coordinates
.values.map(*.tail).Array.&{ (.min, .max)};
my $bottom-min-x = $g.vertex-coordinates
.values.grep(*.tail == $min-y).map(*.head).min;
my $bottom-max-x = $g.vertex-coordinates
.values.grep(*.tail == $min-y).map(*.head).max;
my $top-min-x = $g.vertex-coordinates
.values.grep(*.tail == $max-y).map(*.head).min;
my $top-max-x = $g.vertex-coordinates
.values.grep(*.tail == $max-y).map(*.head).max;# 150.68842025849298Top left node:
my $top-vertex = $g.vertex-coordinates.grep({
.value.head == $top-min-x && .value.tail == $max-y
})».key.head# 255“Weak” diagonal equation:
my ($x1, $y1) = ($bottom-max-x, $min-y);
my ($x2, $y2) = |$g.vertex-coordinates{$top-vertex};
my $k = ($y1 - $y2)/($x1 - $x2);
my $n = -(($x2*$y1 - $x1*$y2)/($x1 - $x2));
sub y-diag(Numeric:D $x) { $k * $x +$n }Get vertices under the diagonal:
my @focus-vertexes = $g.vertex-coordinates.grep({
.value.tail ≤ y-diag(.value.head) + 0.001
})».key;
@focus-vertexes.elems# 499Get the “pyramid” from the filtered vertexes:
my $c-tree = $g.subgraph(@focus-vertexes); # Graph(vertexes => 498, edges => 1395, directed => False)Remove random parts (using neighborhood graphs):
my $c-tree2 = $c-tree.difference(
$c-tree.neighborhood-graph($c-tree.vertex-list.pick(36).grep({
$_ ne $top-vertex
}), d => 1)
);# Graph(vertexes => 498, edges => 975, directed => False)Plot with highlights:
#%html
my @vs = $c-tree2.vertex-degree(:p).grep(*.value≤4)».key;
@vs = @vs.map({ <Snow White GhostWhite>.pick => $_ });
my %highlight = @vs.classify(*.key).nodemap({ $_».value });
$c-tree2.dot(
:%highlight,
node-width => 1.7,
node-height => 1.7,
node-fill-color => 'Red',
node-shape => 'circle',
graph-size => 6,
edge-color => 'Green',
edge-width => 28,
node-font-size => 380,
pad => 2,
node-labels => {$top-vertex => '⭐️', |(($g.vertex-list (-) $top-vertex).keys X=> '')},
engine => 'neato'
):svg
Here are the special graph functionalities used to make the plot above:
- Construction of triangular grid graph
- Subgraph taking
- Neighborhood graphs
- Graph difference
- Graph plotting via Graphviz DOT using:
- Customized styling of various elements
- Vertex coordinates
- Specified vertex labels (see the top of the tree)
- Graph highlighting
- Multiple sets of vertices and edges with different colors can be specified
Conclusion
Graph theory is both very mathematical and very computer-science-ish. It has diverse applications across different fields. So, I urge you to start thinking how to use graphs in all of your Raku and non-Raku projects! (And leverage “Graph”.)