
Introduction
This document provides an overview of Raku packages, as well as related documents and presentations, for doing Data Science using Raku.
This simple mnemonic can be utilized for what Data Science (DS) is while this document is being read:
Data Science = Programming + Statistics + Curiosity
Remark: By definition, anytime we deal with data we do Statistics.
We are mostly interested in DS workflows — the Raku facilitation of using
Large Language Models (LLMs) is seen here as:
- An (excellent) supplement to standard, non-LLM DS workflows facilitation
- A device to use — and solve — Unsupervised Machine Learning (ML) tasks
(And because of our strong curiosity drive, we are completely not shy using LLMs to do DS.)
What is needed to do Data Science?
Here is a wordier and almost technical definition of DS:
Data Science is the process of exploring and summarizing data, uncovering hidden patterns, building predictive models, and creating clear visualizations to reveal insights. It is analytical work analysts, researchers, or scientists would do over raw data in order to understand it and utilize those insights.
Remark: “Utilize insights” would mean “machine learning” to many.
This is the general workflow (or loop) for doing DS:
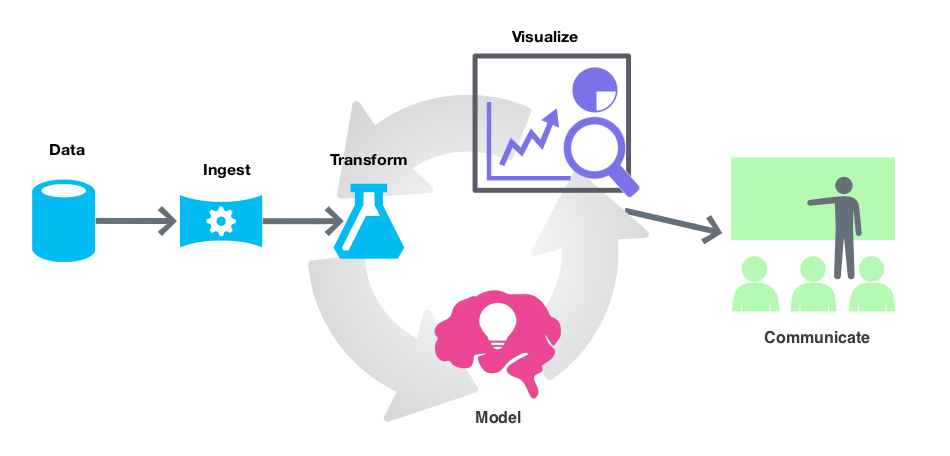
Assume you have a general purpose language which is very good at dealing with text and a package ecosystem with a well maintained part dedicated to doing various Web development tasks and workflows. (I.e. trying to re-live Perl’s glory days.) What new components the ecosystem of that programming language has to be endowed with in order to make it useful for doing DS?
The list below gives such components. They are ranked by importance (most important first), but all are important — i.e. each is “un-skippable” or indispensable.
- Data import and export
- Data wrangling facilitation
- Statistics for data exploration
- Machine Learning algorithms (both unsupervised and supervised)
- Data visualization facilitation
- Interactive computing environment(s)
- Literate programming
Additional, really nice to have, but not indispensable components are:
- Data generation and retrieval
- Interfaces to other programming languages and ecosystems
- Interactive interfaces to parameterized workflows (i.e. dashboards)
- LLM utilization facilitation
Just an overview of packages
This document contains overlapping lists of Raku packages that are used for
performing various types of workflows in DS and related utilization of LLMs.
Remark: The original version of this document, written a year ago, had mostly the purpose of proclaiming (and showing off) Raku’s tooling for DS, ML, and LLMs.
At least half a dozen packages for performing ML or data wrangling in Raku have not been included for three reasons:
- Those packages cannot be installed.
- Mostly, because of external (third party) dependencies.
- When tried or experimented with, the packages do not provide faithful or complete results.
- I.e. precision and recall are not good.
- The functionalities in those packages are two awkward to use in computational workflows.
- It is understandable to have ecosystem packages with incomplete or narrow development state.
- But many of those packages are permanently in those states.
- Additionally, the authors have not shown or documented how the functionalities are used in longer computational chains or real-world use cases.
The examples given below are only for illustration purposes, and by no mean exhaustive. We refer to related blog posts, videos, and package READMEs for more details.
Remark: The packages mentioned in this document can be installed with the script “raku-data-science-install.sh”.
How to read it?
There are three ways to read this document:
- Just look (or maybe, download) the mind map in the next section.
- And the section “Machine Learning & Statistics“.
- Just browse or read the summary list in the next section and skim over the rest of the sections.
- Read all sections and read or browse the linked articles and notebooks.
Actually, it is assumed that many readers would read one random section of this document, hence, most of the sections are mostly self-contained.
Summary of Data Science components and status in Raku
The list below summarizes how Raku covers the Data Science (DS) components listed above. Each component-item has sub-items for its “previous” state (pre-2021), current state (2025), essential-or-not mark, current state 1-to-5 star rating, and references. There are also corresponding table and mind-map.
Remark: Current-state star ratings are, of course, subjective. But I do compare Raku’s DS ecosystem with those of Python, R, and Wolfram Language, and try to be intellectually honest about it.
- Data ingestion
- Comment: This is fundamental, and all programming systems have such functionalities to varying degrees.
- Pre-2021: Robust ingestion of JSON, CSV, and CBOR files; XML and other formats can be ingested, but not in a robust manner.
- 2025: Various improved packages for working with JSON, CSV, markup, images, PDF, etc., with an umbrella ingestion function for them.
- Essential: ✓
- Current status: ★★★ (2.5)
- References: “Data::Importers”, “Data::Translators”, “Omni-slurping with LLMing” [post]
- Data wrangling facilitation
- Comment: Slicing, splitting, combining, aggregating, and summarizing data can be difficult and time-consuming.
- Pre-2021: No serious efforts, especially in terms of streamlining data-wrangling workflows.
- 2025: Two major efforts for streamlining data-wrangling workflows: one using “pure” Raku (good for exploration) and another interfacing with “outside” systems.
- Essential: ✓
- Current status: ★★★ (3.25)
- References: “Data::Reshapers”, “Dan”, “Introduction to data wrangling with Raku” [post]
- Statistics for data exploration
- Comment: This includes descriptive statistics (mean, median, 5-point summary), summarization, outlier identification, and statistical distribution functions.
- Pre-2021: Various attempts; some are basic and “plain Raku” (e.g. “Stats”), some connect to GSL (and do not work on macOS).
- 2025: A couple of major efforts exist: one all-in-one package, the other spread out across various packages.
- Essential: ✓
- Current status: ★★★ (2.5)
- References: “Statistics”, “Statistics::Distributions”, “Statistics::OutlierIdentifiers”, “Data::Summarizers”, “Data::TypeSystem”
- Machine Learning (ML) algorithms (both unsupervised and supervised)
- Comment: Unsupervised ML is often used for Exploratory Data Analysis (EDA); supervised ML is used to leverage data patterns in some way, and also for certain types of EDA.
- Pre-2021: A few packages for unsupervised Machine Learning (ML), such as “Text::Markov”.
- 2025: At least one supervised ML package connecting (binding) to external systems, and a set of unsupervised ML packages for clustering, association-rule learning, fitting, tries with frequencies, and Recommendation Systems (RS). The RS and tries with frequencies can be used as classifiers.
- Essential: ✓
- Current status: ★★★ (2.5)
- References: “Algorithm::XGBoost”, ML::* packages, “Fast and compact classifier of DSL commands” [post], “Chebyshev Polynomials and Fitting Workflows” [post]
- Data visualization facilitation
- Comment: Insightful plots over data are used in Data Science most of the time.
- Pre-2021: A few small packages for plotting, at least one connecting to external systems (like Gnuplot), none of them particularly useful for Data Science.
- 2025: There are two “solid” packages for Data Science visualizations: “JavaScript::D3” and “JavaScript::Google::Charts”. There is also an ASCII-plots package, “Text::Plot”, which is useful when basic, coarse plots are sufficient.
- Essential: ✓
- Current status: ★★★★
- References: “JavaScript::D3”, “JavaScript::Google::Charts”, “Text::Plot”, “The Raku-ju hijack hack for D3.js” , “Geographics data in Raku demo”
- Interactive computing environment(s)
- Comment: Any data exploration is done in an interactive manner, with multiple changes of the data and analysis or pattern-finding workflows.
- Pre-2021: The (basic) Raku REPL, a related Emacs major mode, and the notebook environment “Jupyter::Kernel”.
- 2025: In addition to pre-2021 work, there is “RakuMode” for Wolfram Notebooks, and “Jupyter::Chatbook” for seamless integration with LLMs.
- Essential: ✓
- Current status: ★★★★
- References: “Connecting Mathematica and Raku” [post], “Exploratory Data Analysis with Raku”
- Literate programming (LT)
- Comment: LT is very important for Data Science (DS) because of DS needs for Reproducible Research.
- Pre-2021: None, except “Jupyter::Kernel”, but that is not useful because of the lack of good graphics.
- 2025: LT is fully supported due to having multiple LT solutions, strong graphics capabilities, LLM integration, and computational document converters.
- Essential: ✓
- Current status: ★★★★★ (4.5)
- References: “Notebook transformations” [post], “Raku Literate Programming via command line pipelines” , “Conversion and evaluation of Raku files”
- Data generation and retrieval
- Comment: For didactical and development purposes, random data generation and retrieval of well-known datasets are needed.
- Pre-2021: Nothing more than the built-in Raku random generators (
pick,roll). - 2025: Generators of random strings, words, pet names, date-times, distribution variates, and tabular datasets. Popular datasets from the R ecosystem can be downloaded and cached.
- Essential: 𖧋
- Current status: ★★★★ (3.5)
- References: “Data::Generators”, “Data::ExampleDatasets”, “Data::Geographics”, “Geographics data in Raku demo”
- External Data Science (DS) and Machine Learning (ML) orchestration
- Comment: An effective way to do DS and ML and easily move the developed computations to other systems. This allows reuse and provides confidence that the utilized DS or ML algorithms are properly implemented and fast.
- Pre-2021: Various projects connecting to database systems (e.g. MySQL).
- 2025: The project “Dan” provides bindings to the data-wrangling library Polars. The project “H2O::Client” aims to provide both data-wrangling and ML orchestration to H2O.ai.
- Essential: 𖧋
- Current status: ★★★ (2.5)
- References: “Dan”, “Proc::ZMQed”, “WWW::WolframAlpha”, “H2O::Client”
- Interactive interfaces to parameterized workflows (dashboards)
- Comment: Very useful for getting data insights by dynamically changing different statistics based on parameters.
- Pre-2021: None.
- 2025: An effort, “Air::Examples”, that brings interactivity via HTMX, using the “Cro” package set and templates. Since Google Charts provides interactivity, “JavaScript::Google::Charts” can be extended to have those kinds of controls and dashboards.
- Essential: 𖧋
- Current status: ★
- References: “Air::Examples”, “JavaScript::Google::Charts”
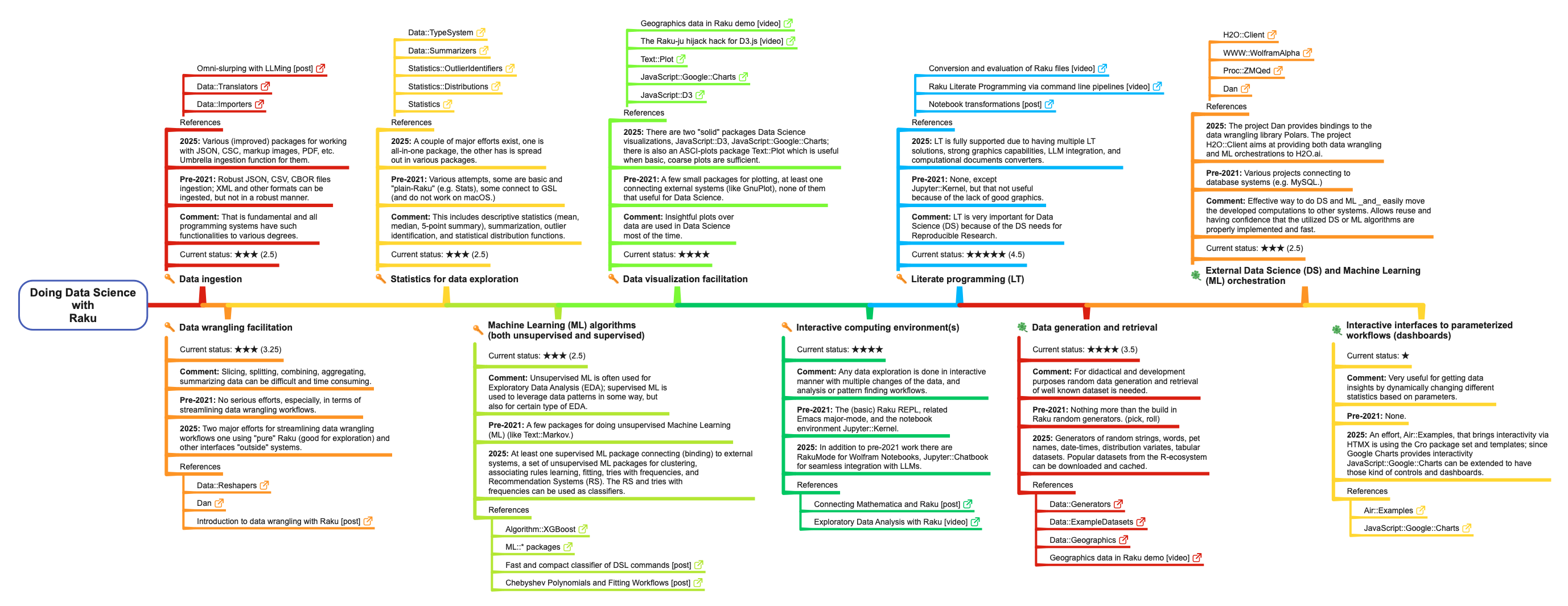
Remark: Mind-map’s PDF file has “life” hyperlinks.
Code generation
For a few years I used Raku to “only” make parser-interpreters for Data Science (DS) and Machine Learning (ML) workflows specified with natural language commands. This is the “Raku for prediction” or “cloths have no emperor” approach; see [AA2]. At some point I decided that Raku has to have its own, useful DS and ML packages. (This document proclaims the consequences of that decision.)
Consider the problem:
Develop conversational agents for Machine Learning workflows that generate correct and executable code using natural language specifications.
The problem is simplified with the observation that the most frequently used ML workflows are in the ML subdomains of:
- Classification
- Latent Semantic Analysis,
- Regression
- Recommendations
In the broader field of DS we also add Data Wrangling.
Each of these ML or DS sub-fields has it own Domain Specific Language (DSL).
There is a set of Raku packages that facilitate the creation of DS workflows in other programming languages. (Julia, Python, R, Wolfram Language.)
The grammar-based ones have the “DSL::” prefix — see, for example, “DSL::English::*” at raku.land.
The LLM based packages are “ML::NLPTemplateEngine” and “DSL::Examples”.
Examples
Here is an example of using the Command Line Interface (CLI) script of “ML::NLPTemplateEngine”:
concretize --l=Python make a quantile regression pipeline over dfTemperature using 24 knots an interpolation order 2
# qrObj = (Regressionizer(dfTemperature)
# .echo_data_summary()
# .quantile_regression(knots = 24, probs = [{0.25, 0.5, 0.75}], order = 2)
# .plot(date_plot = False)
# .errors_plot(relative_errors = False, date_plot = False))
Data wrangling
Most data scientists spend most of their time doing data acquisition and data wrangling. Not Data Science, or AI, or whatever “really learned” work. (For a more elaborated rant, see “Introduction to data wrangling with Raku”, [AA2].)
Data wrangling, summarization, and generation is done with the packages:
Example datasets retrieval is done with the package:
Generation of data wrangling workflows code is done with the package:
the functionalities of which are summarized in this diagram:
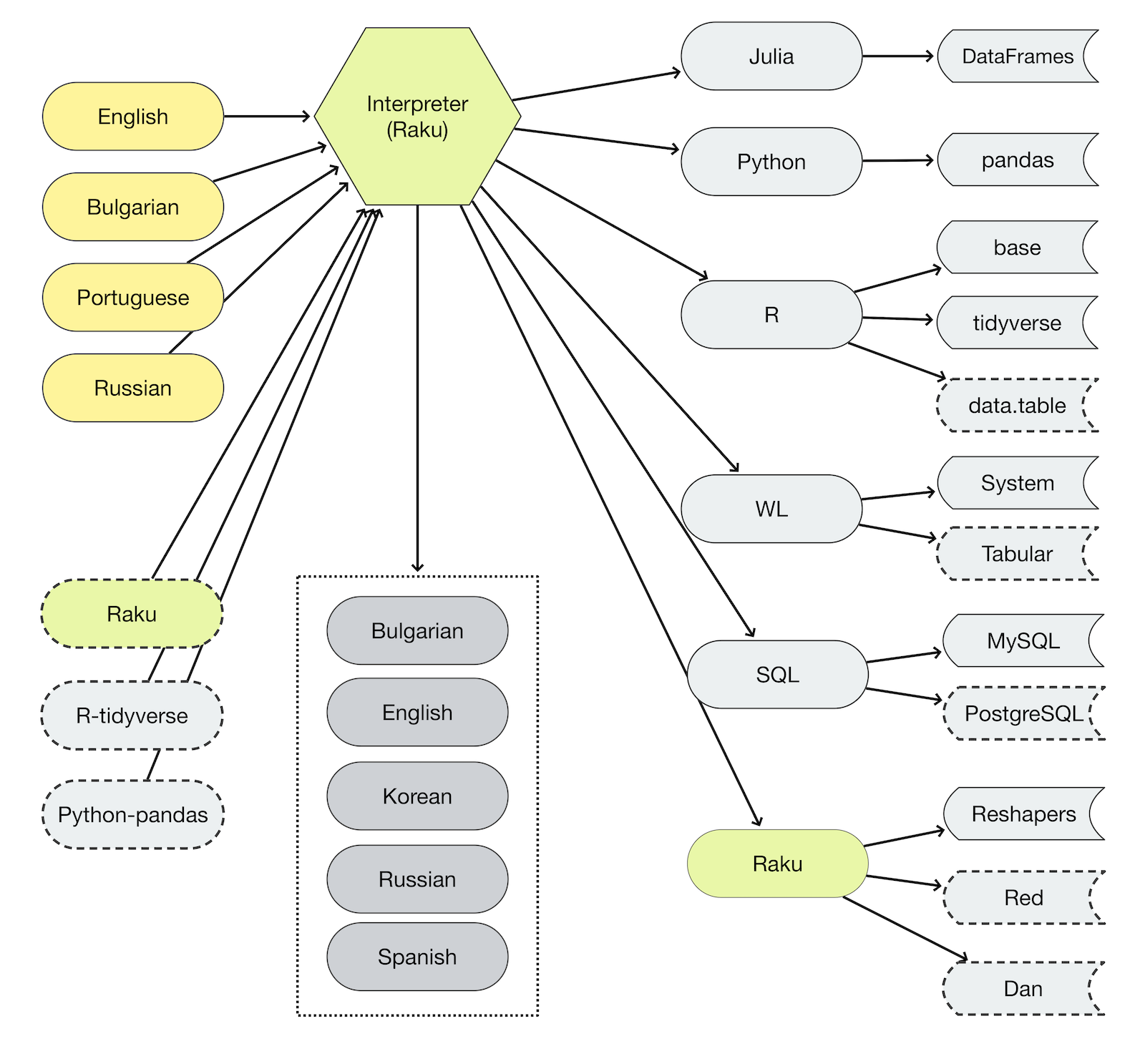
Examples
Data wrangling with “Data::Reshapers”:
use Data::Reshapers;
my @dsTitanic = get-titanic-dataset();
cross-tabulate(@dsTitanic, <passengerSex>, <passengerSurvival>)
# {female => {died => 127, survived => 339}, male => {died => 682, survived => 161}}
Data wrangling code generation via CLI:
dsl-translation -l=Raku "use @dsTitanic; group by passengerSex; show the counts"
# $obj = @dsTitanic ;
# $obj = group-by($obj, "passengerSex") ;
# say "counts: ", $obj>>.elems
Exploratory Data Analysis
At this point Raku is fully equipped to do Exploratory Data Analysis (EDA) over small to moderate size datasets. (E.g. less than 100,000 rows.) See [AA4, AAv5].
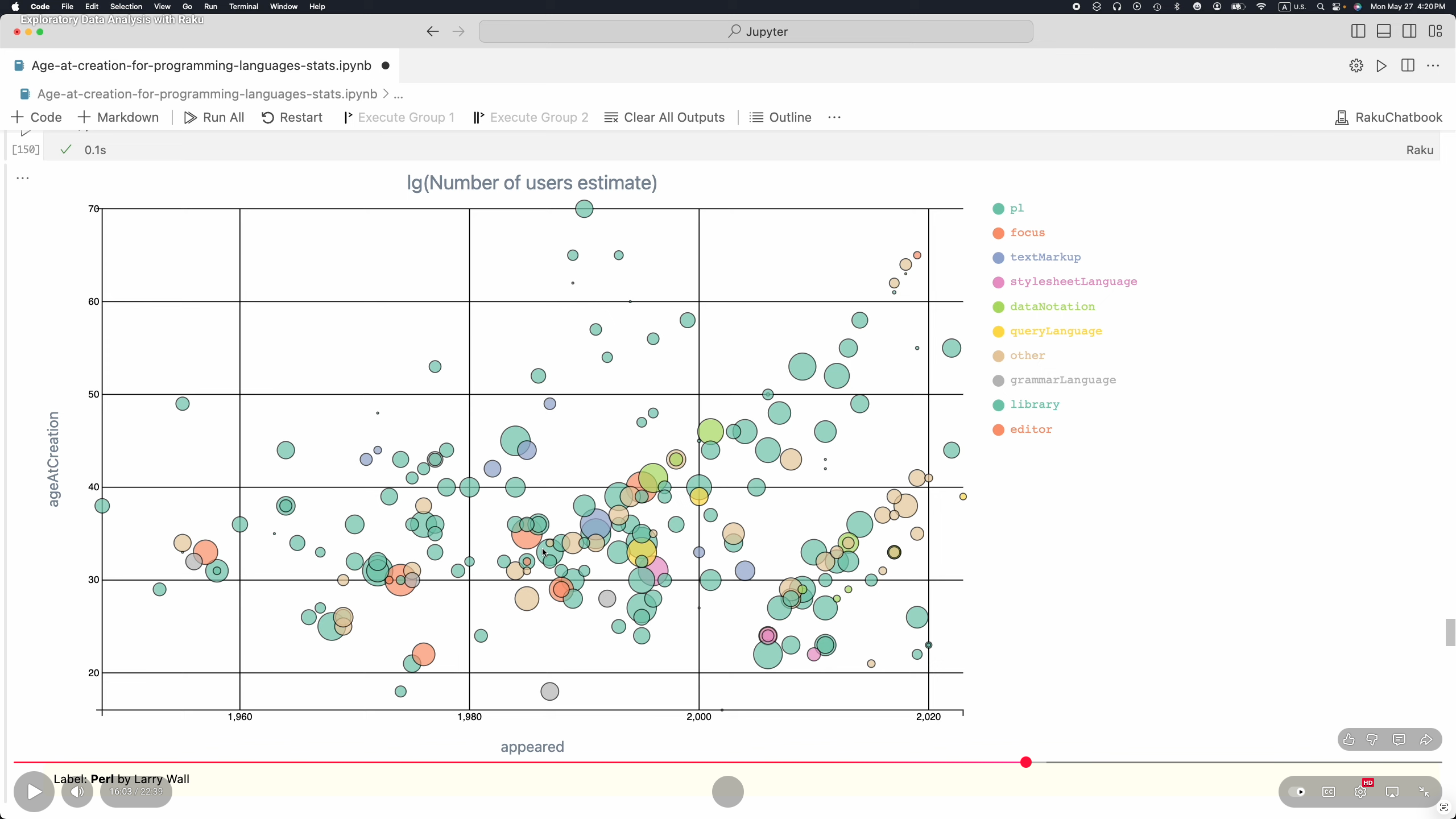
Here are EDA stages and related Raku packages:
- Easy data ingestion
- “Data::Importers”
allows for “seamless” import different kinds of data (files or URLs) via:
- “Data::Importers”
- Data wrangling
- See the previous section
- Visualization
- “JavaScript::D3”, [AAv4]
- “JavaScript::Google::Charts”, [AAv5]
- Example- and factual data:
- I.e. data ready to do computations with
- “Data::ExampleDatasets”
- “Data::Geographics”, [AAv5]
- The following entity packages provide concrete names of entities of different kinds:
- The entity packages have grammar roles for gazetteer Named Entity Recognition (NER)
- Interactive development environment(s)
- These are often referred to as “notebook solutions”
- “Jupyter::Kernel”
- “Jupyter::Chatbook”
- “RakuMode”
Machine Learning & Statistics
The topics of Machine Learning (ML) and Statistics are too big to be described with more than an outline in this document. The curious or studious readers can check or read and re-run the notebooks [AAn2, AAn3, AAn4].
Here are Raku packages for doing ML and Statistics:
- Unsupervised learning
- Supervised learning
- Fitting / regression
- Distributions
- Outliers

Remark: Again, mind-map’s PDF file has “life” hyperlinks.
Recommender systems and sparse matrices
I make Recommender Systems (RS) often during Exploratory Data Analysis (EDA). For me, RS are “first order regression.” I also specialize in the making of RS. I prefer using RS based on Sparse Linear Algebra (SMA) because of the fast computations, easy interpretation, and reuse in other Data Science (DS) or Machine Learning (ML) workflows. I call RS based on SMA Sparse Matrix Recommenders (SMRs) and I have implemented SMR packages in Python, R, Raku, and Wolfram Language (WL) (aka Mathematica.)
Remark: The main reason I did not publish the original version of this document a year ago is because Raku did not have SMA and SMR packages.
Remark: The making of LLM-based RS is supported in Raku via Retrieval Augment Generation (RAG); see “Raku RAG demo”, [AAv9].
I implemented a Raku recommender without SMA, “ML::StreamsBlendingRecommender”, but it is too slow for “serious” datasets. Still useful; see [AAv1].
SMA is a “must have” for many computational workflows. Since I really like having matrices (sparse or not) with named rows and columns and I have implemented packages for sparse matrices with named rows and columns in Python, Raku, and WL.
Remark: Having data frames and matrices with named rows and columns is central feature of R. Since I find that really useful from both DS-analytical and software-engineering-architectural points of view I made corresponding implementations in other programming languages.
After implementing the SMA package “Math::SparseMatrix” I implemented (with some delay) the SMR package, “ML::SparseMatrixRecommender”. (The latter one is a very recent addition to Raku’s ecosystem, just in time for this document’s publication.)
Examples
Here is an example of using Raku to generate code for one of my SMR packages:
dsl-translation -t=Python "
create from dsData;
apply LSI functions IDF, None, Cosine;
recommend by profile for passengerSex:male, and passengerClass:1st;"
# obj = (SparseMatrixRecommender()
# .create_from_wide_form(data = dsData)
# .apply_term_weight_functions(global_weight_func = "IDF", local_weight_func = "None", normalizer_func = "Cosine")
# .recommend_by_profile( profile = ["passengerSex:male", "passengerClass:1st"]))
Literate programming
“Literate Programming (LP)” tooling is very important for doing Data Science (DS). At this point Raku has four LP solutions (three of them are “notebook solutions”):
The Jupyter Raku-kernel packages “Jupyter::Kernel” and “Jupyter::Chatbook” provide cells for rendering the output of LaTeX, HTML, Markdown, or Mermaid-JS code or specifications; see [AAv2].
The package “Text::CodeProcessing” can be used to “weave” (or “execute”) computational documents that are Markdown-, Org-mode-, or Pod6 files; see [AAv2].
“RakuMode” is a Wolfram Language (WL) paclet for using Raku in WL notebooks.
(See the next section for the “opposite way” — using WL in Raku sessions.)
Remark: WL is also known as “Mathematica”.
The package “Markdown::Grammar” can be used in notebook conversion workflows; see [AA1, AAv1].
Remark: This document itself is a “computational document” — it has executable Raku and Shell code cells. The published version of this document was obtained by “executing it” with the command:
file-code-chunks-eval Raku-for-Data-Science-and-LLMs.md
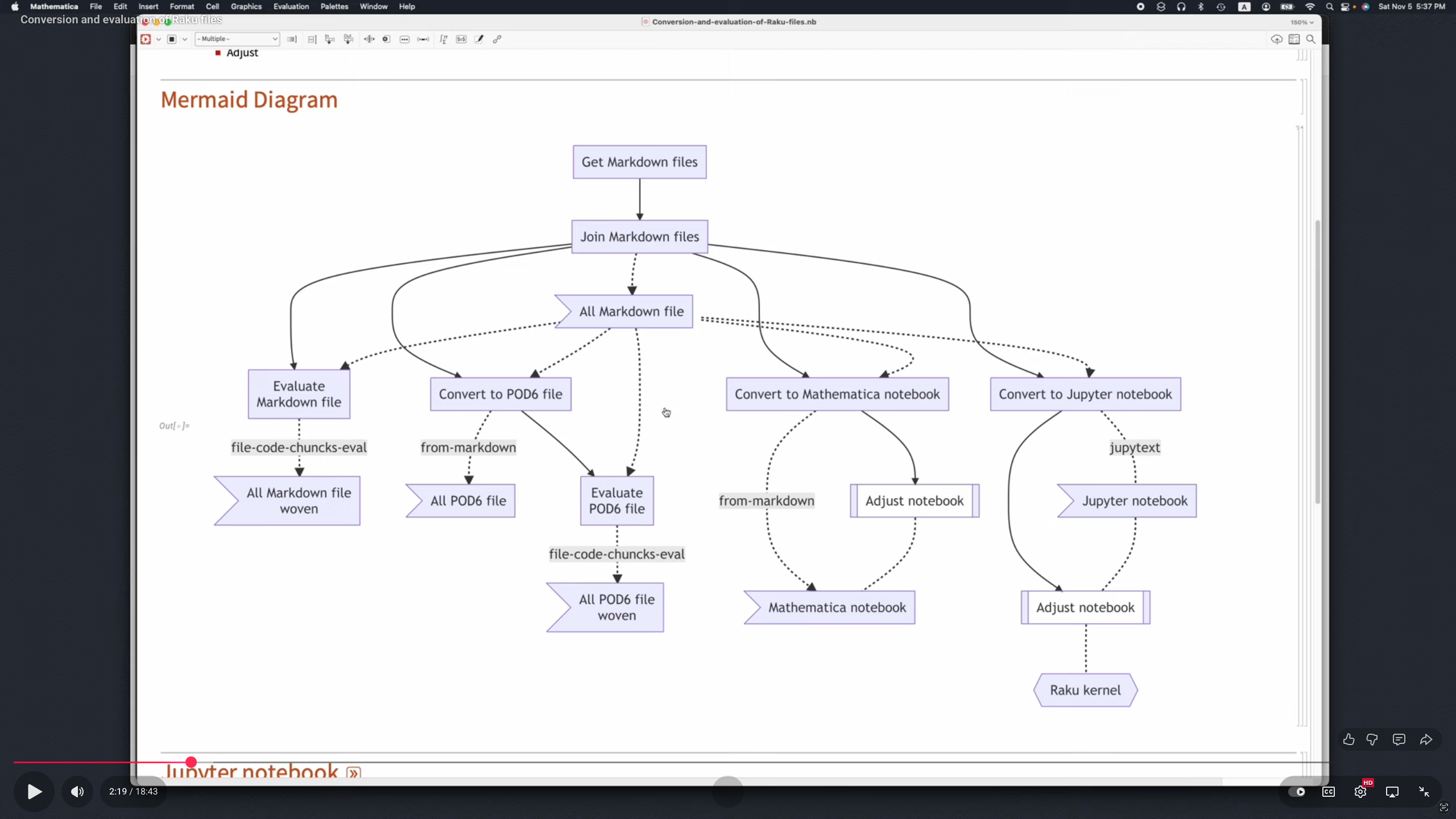
Interconnections
A nice complement to the Raku’s DS and LLM functionalities is the ability to easily connect to other computational systems like Python, R, or Wolfram Language (WL).
The package “Proc::ZMQed” allows the connection to Python, R, and WL via ZeroMQ; see [AAv3].
The package “WWW::WolframAlpha” can be used to get query answers from WolframAlpha (W|A). Raku chatbooks have also magic cells for accessing W|A; see [AA3].
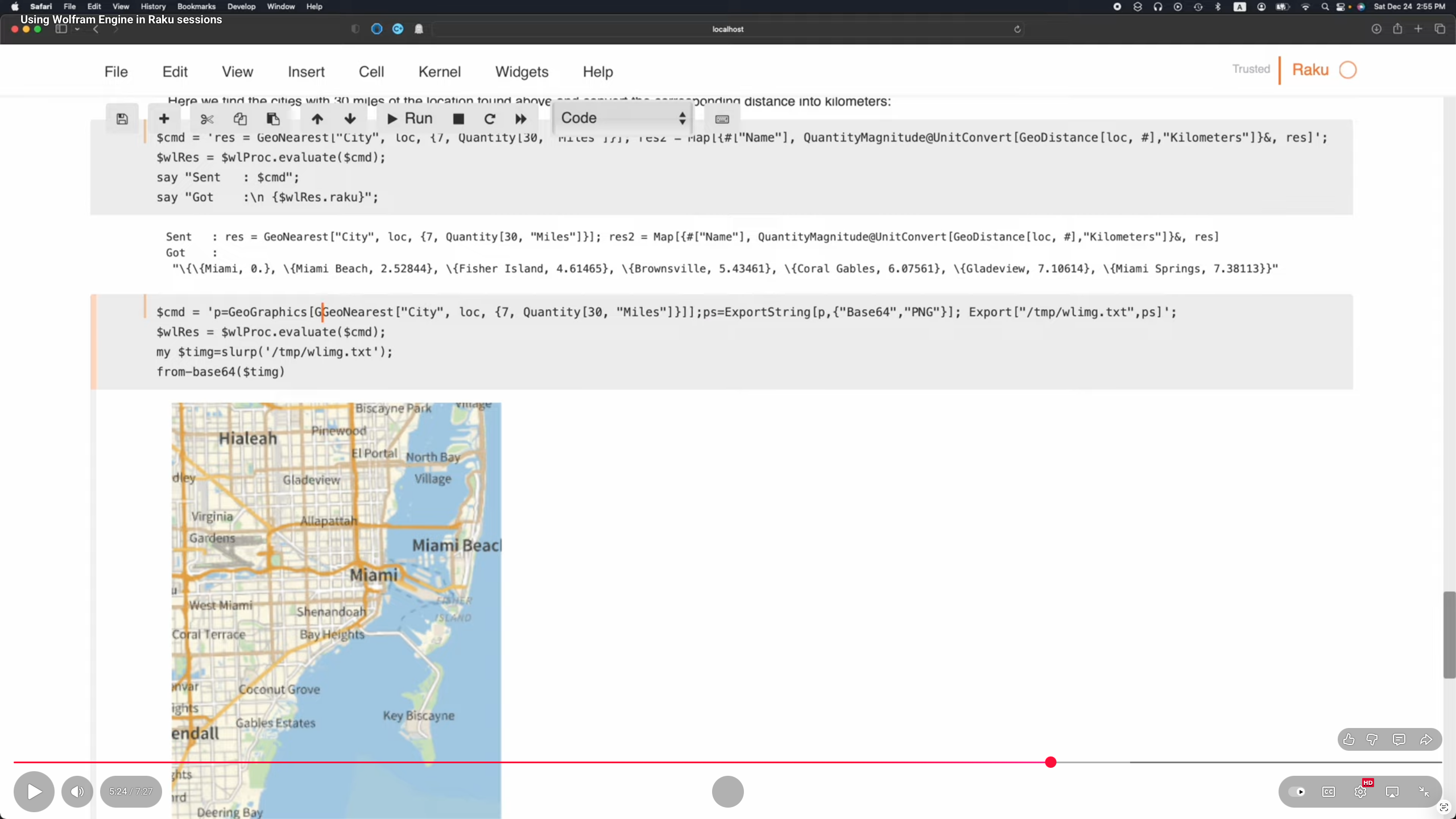
Cross language workflows
The packages listed in this document, along with the related articles and videos,
support and demonstrate computational workflows that work across different programming languages.
- Data wrangling workflows code generation is for Julia, Python, R, Raku, SQL, and Wolfram Language (WL).
- Raku’s data wrangling functionalities adhere the DSLs and workflows of the popular Python “pandas” and R “tidyverse”.
- More generally, ML workflows code generators as a rule target R, Python, and WL.
- At this point, only recommender systems Raku-code is generated.
- The Raku DSL for interacting with LLMs is also implemented in Python and WL; see [AAv8].
- To be clear, WL’s design of LLM functions was copied (or transferred) to Raku.
References
Articles, blog posts
[AA1] Anton Antonov, “Connecting Mathematica and Raku”, (2021), RakuForPrediction at WordPress.
[AA2] Anton Antonov, “Introduction to data wrangling with Raku”, (2021), RakuForPrediction at WordPress.
[AA3] Anton Antonov, “Notebook transformations”, (2024), RakuForPrediction at WordPress.
[AA4] Anton Antonov, “Omni-slurping with LLMing”, (2024), RakuForPrediction at WordPress.
[AA5] Anton Antonov, “Chatbook New Magic Cells”, (2024), RakuForPrediction at WordPress.
[AA6] Anton Antonov, “Age at creation for programming languages stats”, (2024), RakuForPrediction at WordPress.
Notebooks
[AAn1] Anton Antonov, “Connecting Raku with Wolfram Language and Mathematica”, (2021), Wolfram Community.
[AAn2] Anton Antonov, “Data science over small movie dataset — Part 1”, (2025), RakuForPrediction-blog at GitHub.
[AAn3] Anton Antonov, “Data science over small movie dataset — Part 1”, (2025), RakuForPrediction-blog at GitHub.
[AAn4] Anton Antonov, “Data science over small movie dataset — Part 3”, (2025), RakuForPrediction-blog at GitHub.
Videos
[AAv1] Anton Antonov, “Markdown to Mathematica converter (Jupyter notebook example)”, (2022), YouTube/AAA4prediction.
[AAv2] Anton Antonov, “Conversion and evaluation of Raku files”, (2022), YouTube/AAA4prediction.
[AAv3] Anton Antonov, “Using Wolfram Engine in Raku sessions”, (2022), YouTube/AAA4prediction.
[AAv4] Anton Antonov, “LLaMA models running guide (Raku)”, (2024), YouTube/AAA4prediction.
[AAv5] Anton Antonov, “Conversion and evaluation of Raku files”, (2024), YouTube/AAA4prediction.
[AAv6] Anton Antonov, “Raku Literate Programming via command line pipelines”, (2024), YouTube/AAA4prediction.
[AAv7] Anton Antonov, “Exploratory Data Analysis with Raku”, (2024), YouTube/AAA4prediction.
[AAv8] Anton Antonov, “Geographics data in Raku demo”, (2024), YouTube/AAA4prediction.
[AAv9] Anton Antonov, “Raku RAG demo”, (2024), YouTube/AAA4prediction.
[AAv10] Anton Antonov, “Robust LLM pipelines (Mathematica, Python, Raku)”, (2024), YouTube/AAA4prediction.
[AAv11] Anton Antonov, “TRC 2022 Implementation of ML algorithms in Raku”, (2022), YouTube/antononcube.

One thought on “Day 2 – Doing Data Science with Raku”